Table of Contents
This page gives us an brief introduction to each of the AWS Glue components and the key concepts and features, such as logging and monitoring, and automation, that we should know before authoring ETL jobs.
It is divided into following parts:
- AWS Glue
- AWS Glue Use Cases
- AWS Glue Architecture
- AWS Glue Components
- AWS Glue features and concepts
- Summary
AWS Glue
- AWS Glue is a fully managed serverless ETL (extract, transform, and load) service that makes it simple and cost-effective to categorize our data, clean it, enrich it, and move it reliably between various data stores and data streams.
- AWS Glue consists of a central metadata repository known as the AWS Glue Data Catalog, an ETL engine that automatically generates Python or Scala code, and a flexible scheduler that handles dependency resolution, job monitoring, and retries.
- AWS Glue is serverless, so we don’t need to set up any cluster or infrastructure, and we can scale up and down as we need. AWS Glue charges only for the amount of compute time it needs to finish a specific workload.
- AWS Glue is designed to work with semi-structured data. It’s common to want to convert semi-structured data into relational tables. Conceptually, we are flattening a hierarchical schema to a relational schema. AWS Glue can perform this conversion for us on-the-fly.
- It introduces a component called a dynamic frame, which we can use in our ETL scripts. A dynamic frame is similar to an Apache Spark dataframe, which is a data abstraction used to organize data into rows and columns, except that each record is self-describing so no schema is required initially. With dynamic frames, we get schema flexibility and a set of advanced transformations specifically designed for dynamic frames. We can convert between dynamic frames and Spark dataframes, so that we can take advantage of both AWS Glue and Spark transformations to do the kinds of analysis that we want.
- We can use the AWS Glue console to discover data, transform it, and make it available for search and querying.
- We can also use the AWS Glue API operations to interface with AWS Glue services.
- We can use a familiar development environment to edit, debug, and test our Python or Scala Apache Spark ETL code.
AWS Glue Use Cases
- We can use AWS Glue to organize, cleanse, validate, and format data for storage in a data warehouse or data lake.
- We can use AWS Glue when we run serverless queries against our Amazon S3 data lake.
- We can create event-driven ETL pipelines with AWS Glue.
- We can use AWS Glue to understand our data assets.
AWS Glue Architecture
The following diagram shows the architecture of an AWS Glue environemnt:
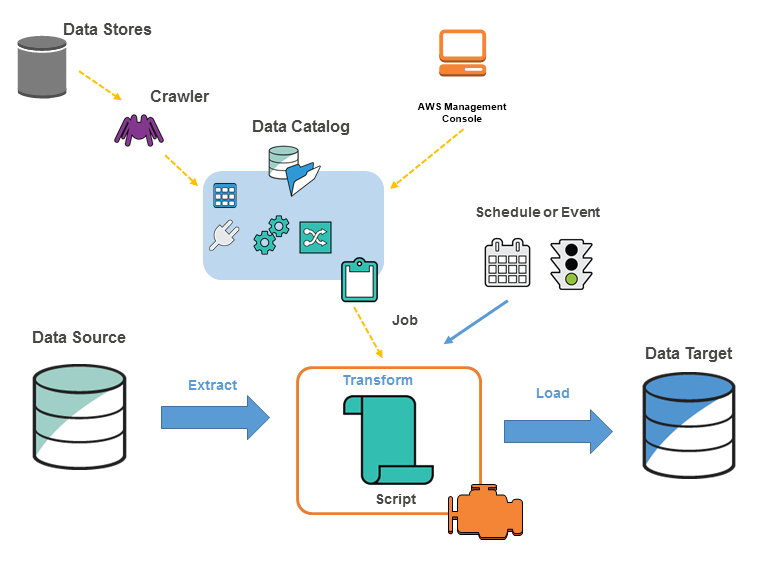
We typically perform the following actions:
- For data store sources, we define a crawler to populate our AWS Glue Data Catalog with metadata table definitions. We point our crawler at a data store, and the crawler creates table definitions in the Data Catalog. For streaming sources, we manually define Data Catalog tables and specify data stream properties. In addition to table definitions, the AWS Glue Data Catalog contains other metadata that is required to define ETL jobs. We use this metadata when we define a job to transform our data.
- AWS Glue can generate a script to transform our data. Or, we can provide the script in the AWS Glue console or API.
- We can run our job on demand, or we can set it up to start when a specified trigger occurs. The trigger can be a time-based schedule or an event. When our job runs, a script extracts data from our data source, transforms the data, and loads it to our data target. The script runs in an Apache Spark environment in AWS Glue.
IMPORTANT:
- Tables and databases in AWS Glue are objects in the AWS Glue Data Catalog. They contain metadata; They do NOT contain data from a data store.
- Text-based data, such as CSVs, must be encoded in
UTF-8for AWS Glue to process it successfully.
AWS Glue Components
AWS Glue relies on the interaction of several components to create and manage our extract, transfer, and load (ETL) workflow.
AWS Glue consists of the following components:
- AWS Glue ETL – AWS Glue ETL gives us batch and streaming options to author code and move, transform, and aggregate data from one source to another.
- AWS Glue Data Catalog – Data Catalog provides a view of the metadata of all our data along with options to crawl specific data sources.7
- AWS Glue DataBrew – DataBrew is a visual data preparation tool that data analysts and data scientists can use to clean and normalize data. We can choose from more than 250 prebuilt transformations to automate data preparation tasks, all without the need to write any code.
AWS Glue ETL
- You can use AWS Glue ETL to move, clean, and transform data from one source to another by using its own functions, Apache Spark, and Python.
- Using the metadata in the Data Catalog, AWS Glue can automatically generate Scala or PySpark (the Python API for Apache Spark) scripts with AWS Glue extensions that we can use and modify to perform various ETL operations.
- For example, we can extract, clean, and transform raw data, and then store the result in a different repository, where it can be queried and analyzed. Such a script might convert a CSV file into a relational form and save it in Amazon Redshift.
- We should use Glue ETL when we do not need or want to pay for an EMR cluster
AWS Glue ETL code can be authored in the following ways:
- Python shell - When the size of the data is very small, we can use Python shell to write Python scripts to manipulate data.
- Spark – We can use Scala and Python to author ETL jobs with AWS Glue and Apache Spark.
- Spark Streaming – To enrich, aggregate, and combine streaming data, we can use streaming ETL jobs. In AWS Glue, streaming ETL jobs run on the Apache Spark Structured Streaming engine.
- AWS Glue Studio – If someone is new to Apache Spark programming or is accustomed to ETL tools with boxes-and-arrows interfaces, get started by using AWS Glue Studio.
DPUs and worker types
- AWS Glue uses the concept of concurrent data processing units (DPUs) to describe the compute capacity of a job run, which are also known as worker types. DPUs can be allocated based on the data and velocity needs of a specific use case.
AWS Glue Python or Scala on Apache Spark Instead of juggling between various instance types to match a workload, AWS Glue comes with the capability of choosing between three worker types recommended for various workloads: Standard, G.1X (for memory-intensive workloads) and G.2X (for workloads with ML transforms).
The following table shows the different AWS Glue worker types for the Apache Spark run environment for batch, streaming, and AWS Glue Studio workloads.
| Standard | G.1X | G.2X | |
|---|---|---|---|
| vCPU | 4 | 4 | 4 |
| Memory | 16 GB | 16 GB | 32 GB |
| Disc space | 50 | 64 | 128 |
| Memory | 2 | 1 | 1 |
Note: With AWS Glue Studio we can use only G.1X and G.2X worker types.
AWS Glue Streaming ETL
- AWS Glue enables us to perform ETL operations on streaming data using continuously-running jobs.
- AWS Glue streaming ETL is built on the Apache Spark Structured Streaming engine, and can ingest streams from Amazon Kinesis Data Streams, Apache Kafka, and Amazon Managed Streaming for Apache Kafka (Amazon MSK).
- Streaming ETL can clean and transform streaming data and load it into Amazon S3 or JDBC data stores.
- Use Streaming ETL in AWS Glue to process event data like IoT streams, clickstreams, and network logs.
- If we know the schema of the streaming data source, we can specify it in a Data Catalog table. If not, we can enable schema detection in the streaming ETL job. The job then automatically determines the schema from the incoming data.
- The streaming ETL job can use both AWS Glue built-in transforms and transforms that are native to Apache Spark Structured Streaming.
AWS Glue Jobs
- Job is the business logic that is required to perform ETL work. It is composed of a transformation script, data sources, and data targets. Job runs are initiated by triggers that can be scheduled or triggered by events.
- The AWS Glue Jobs system provides managed infrastructure to orchestrate our ETL workflow.
- We can create jobs in AWS Glue that automate the scripts we use to extract, transform, and transfer data to different locations. - Jobs can be scheduled and chained, or they can be triggered by events such as the arrival of new data.
- Glue jobs output file formats JSON, CSV, ORC (Optimized Row Columnar), Apache Parquet, and Apache Avro
Glue ETL Jobs - Transformations Glue has built-in transforms for processing data
- Call from within our ETL script
- In a DynamicFrame (an extension of an Apache Spark SQL DataFrame), our data passes from transfrom to transform
- Built-in transform types (subset)
- ApplyMapping: maps source DynamicFrame columns and data types to target DynamicFrame columns and data types
- Filter: selects records from a DynamicFrame and returns a filtered DynamicFrame
- Map: applies a function to the records of a DynamicFrame and returns a transformed DynamicFrame
- Relationalize: converts a DynamicFrame to a relational (rows and columns) form
- Machine Learning Transformations
- FindMatches ML: identify duplicate or matching records in our dataset, even when the records do not have a common unique identifier and no fields match exactly
- Format conversions: CSV, JSON, Avro, Parquet, ORC, XML
- Apache Spark transformations, e.g. K-Means
AWS Glue Dynamic Frame
- A distributed table that supports nested data such as structures and arrays.
- Each record is self-describing, designed for schema flexibility with semi-structured data.
- Each record contains both data and the schema that describes that data.
- We can use both dynamic frames and Apache Spark DataFrames in our ETL scripts, and convert between them.
- Dynamic frames provide a set of advanced transformations for data cleaning and ETL.
AWS Glue Data Catalog
- AWS Glue Data Catalog is our persistent metadata store. It is a managed service that lets us store, annotate, and share metadata in the AWS Cloud in the same way we would in an Apache Hive metastore.
- Each AWS account has one AWS Glue Data Catalog per AWS region.
- It provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos, and use that metadata to query and transform the data.
- We can use AWS Identity and Access Management (IAM) policies to control access to the data sources managed by the AWS Glue Data Catalog. IAM policies let us clearly and consistently define which users have access to which data, regardless of its location.
- The Data Catalog also provides comprehensive audit and governance capabilities, with schema change tracking and data access controls. We can audit changes to data schemas. This helps ensure that data is not inappropriately modified or inadvertently shared.
The following are other AWS services and open source projects that use the AWS Glue Data Catalog:
- AWS Lake Formation
- Amazon Athena
- Amazon Redshift Spectrum
- Amazon EMR
- AWS Glue Data Catalog Client for Apache Hive Metastore
The AWS Glue Data Catalog consists of the following components:
- Databases and tables
- Crawlers and classifiers
- Connections
- AWS Glue Schema Registry
AWS Glue databases and tables
- The Data Catalog consists of database and tables.
- A table can be in only one database.
- Our database can contain tables from many different sources that AWS Glue supports.
We can create the database and tables in the following ways:
- The AWS Glue crawler
- An AWS Glue ETL job
- AWS Glue console
- The
CreateTableoperation in the AWS Glue API - AWS CloudFormation templates
- A migrated Apache Hive metastore
Note: Currently, AWS Glue supports Amazon Simple Storage Service (Amazon S3), Amazon DynamoDB, and Java Database Connectivity (JDBC) data sources.
AWS Glue crawlers and classifiers
- A crawler helps create and update the Data Catalog tables.
- It can crawl both file-based and table-based data stores.
Crawlers can crawl the following data stores through their respective native interfaces:
- Amazon S3
- DynamoDB
Crawlers can crawl the following data stores through a JDBC connection:
- Amazon Redshift
- Amazon Relational Database Service (Amazon RDS)
- Amazon Aurora
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- Publicly accessible databases (on-premises or on another cloud provider environment)
- Aurora
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
Populating the AWS Glue Data Catalog
- The AWS Glue Data Catalog contains references to data that is used as sources and targets of our extract, transform, and load (ETL) jobs in AWS Glue. To create our data warehouse or data lake, we must catalog this data.
- The AWS Glue Data Catalog is an index to the location, schema, and runtime metrics of our data.
- We use the information in the Data Catalog to create and monitor our ETL jobs.
- Information in the Data Catalog is stored as metadata tables, where each table specifies a single data store. Typically, we run a crawler to take inventory of the data in our data stores, but there are other ways to add metadata tables into our Data Catalog.
The following workflow diagram shows how AWS Glue crawlers interact with data stores and other elements to populate the Data Catalog:
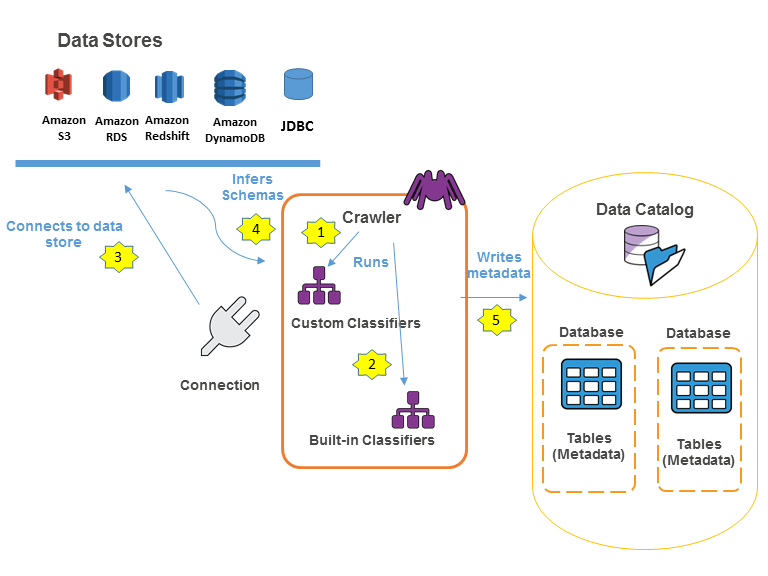
The following is the general workflow for how a crawler populates the AWS Glue Data Catalog:
- A crawler runs any custom classifiers that we choose to infer the format and schema of our data. We provide the code for custom classifiers, and they run in the order that we specify. The first custom classifier to successfully recognize the structure of our data is used to create a schema. Custom classifiers lower in the list are skipped.
- If no custom classifier matches our data’s schema, built-in classifiers try to recognize our data’s schema. An example of a built-in classifier is one that recognizes JSON.
- The crawler connects to the data store. Some data stores require connection properties for crawler access.
- The inferred schema is created for our data.
- The crawler writes metadata to the Data Catalog. A table definition contains metadata about the data in our data store. The table is written to a database, which is a container of tables in the Data Catalog. Attributes of a table include classification, which is a label created by the classifier that inferred the table schema.
AWS Glue connections
- We can use connections to define connection information, such as login credentials and virtual private cloud (VPC) IDs, in one place. This saves time, because we don’t need to provide connection information every time we create a crawler or job.
The following connection types are available:
- JDBC
- Amazon RDS
- Amazon Redshift
- MongoDB, including Amazon DocumentDB (with MongoDB compatibility)
- Network (designates a connection to a data source within a VPC environment on AWS)
AWS Glue Schema Registry
- The AWS Glue Schema Registry enables disparate systems to share a schema for serialization and deserialization.
With the AWS Glue Schema Registry, we can manage and enforce schemas on our data streaming applications using convenient integrations with the following data input sources:
- Apache Kafka
- Amazon Managed Streaming for Apache Kafka
- Amazon Kinesis Data Streams
- Amazon Kinesis Data Analytics for Apache Flink
- AWS Lambda
Schema Registry consists of the following components:
- Schemas – A schema is the abstraction to represent the structure and format of a data record.
- Registry – A registry is a logical container of schemas. Registries allow us to organize your schemas and manage access control for our applications.
AWS Glue DataBrew
- AWS Glue DataBrew differs from AWS Glue ETL in that we don’t have write code to work with it.
- A visual data preparation tool to clean and normalize data
- UI for pre-processing large data sets
- Input from S3, data warehouse, or database
- Output to S3
- Over 250 read-made transformations avaiable
- You create steps of transformations that can be saved as jobs within a larger project
- Security:
- KMS
- SSL in transit
- IAM can restrict who can do what
- CloudWatch & CloudTrail
DataBrew is available in a separate console view from AWS Glue. It works with the following services:
- AWS Data Exchange
- AWS Glue Data Catalog
- AWS Lake Formation
- Amazon RDS
- Amazon Redshift
- Amazon S3
AWS Glue Important features and concepts
- With AWS Glue, we can debug, monitor performance, and automate and run jobs in the same S3 bucket without re-running a job on the same set of data.
Logging and monitoring
- By default, AWS Glue sends logs to Amazon CloudWatch under the
aws-gluelog group.
In addition to the default logs, AWS Glue provides the following options for more advanced level monitoring:
- Job metrics – After we turn on Job metrics, metrics are reported every 30 seconds to the Glue namespace.
- Continuous logging – AWS Glue provides real-time, continuous logging for AWS Glue jobs. We can view real-time Apache Spark job logs in CloudWatch, including driver logs, executor logs, and an Apache Spark job progress bar.
- Spark UI – When our AWS Glue ETL job runs using Spark, we can store Spark UI logs. We can then deploy the Spark history server to view them on an Amazon Elastic Compute Cloud (Amazon EC2) instance. We could also view them locally using Docker.
Note: Monitoring options are not available for Python shell jobs.
Automation
AWS Glue provides two ways for us to automate ETL jobs:
- AWS Glue triggers - We can design a basic chain of dependent jobs and crawlers based on a specific schedule or condition by using AWS Glue triggers.
- AWS Glue workflows - For more complex workloads, we can use workflows to create and visualize complex ETL activities that involve multiple crawlers, jobs, and triggers. Each workflow manages running and monitoring all its components.
Integration with other AWS services
- AWS Glue also integrates with other AWS services, such as Lambda and AWS Step Functions, for more automation options.
Job bookmarks
- To avoid reprocessing data when a scheduled ETL job runs, AWS Glue uses job bookmarks.
- AWS Glue tracks data that has already been processed during a previous run of an ETL job by persisting state information from the job run.
- The persisted state information is the job bookmark.
- Job bookmarks help AWS Glue maintain state information and prevent the reprocessing of old data.
- Persists state from the job run
- Allows you to proces new data only when re-running on schedule
- Works with S3 sources in a variety of formats
- Works with JDBC (if PK’s are in sequential order)
- IMPORTANT: Only handles new rows, NOT updated rows
Summary
Usage Patterns
- AWS Glue can automatically crawl our data and generate code to execute or data transformations and loading processes.
- Integration with services like Amazon Athena, Amazon EMR, and Amazon Redshift
- Serverless, no infrastructure to provision or manage
- AWS Glue generates ETL code that is customizable, reusable, and portable, using familiar technology – Python and Spark.
Cost Model
- With AWS Glue, we pay an hourly rate, billed by the minute, for crawler jobs (discovering data) and ETL jobs (processing and loading data).
- For the AWS Glue Data Catalog, we pay a simple monthly fee for storing and accessing the metadata. The first million objects stored are free, and the first million accesses are free. If we provision a development endpoint to interactively develop our ETL code, we pay an hourly rate, billed per minute.
Performance
- AWS Glue uses a scale-out Apache Spark environment to load our data into its destination.
- We can simply specify the number of Data Processing Units (DPUs) that we want to allocate to our ETL job. An AWS Glue ETL job requires a minimum of 2 DPUs. By default, AWS Glue allocates 10 DPUs to each ETL job. Additional DPUs can be added to increase the performance of our ETL job.
- Multiple jobs can be triggered in parallel or sequentially by triggering them on a job completion event.
- We can also trigger one or more AWS Glue jobs from an external source such as an AWS Lambda function.
Durability and Availablity
- AWS Glue connects to the data source of our preference, whether it is in an Amazon S3 file, an Amazon RDS table, or another set of data. As a result, all our data is stored and available as it pertains to that data stores durability characteristics.
- The AWS Glue service provides status of each job and pushes all notifications to Amazon CloudWatch events. We can setup SNS notifications using CloudWatch actions to be informed of job failures or completions.
Scalability and Elasticity
- AWS Glue provides a managed ETL service that runs on a Serverless Apache Spark environment. This allows us to focus on our ETL job and not worry about configuring and managing the underlying compute resources.
- AWS Glue works on top of the Apache Spark environment to provide a scale-out execution environment for our data transformation jobs.
Interfaces
- AWS Glue provides a number of ways to populate metadata into the AWS AWS Glue Data Catalog. AWS Glue crawlers scan various data stores we own to automatically infer schemas and partition structure and populate the AWS AWS Glue Data Catalog with corresponding table definitions and statistics.
- We can also schedule crawlers to run periodically so that our metadata is always up-to-date and in-sync with the underlying data. Alternately, we can add and update table details manually by using the AWS Glue Console or by calling the API.
- We can also run Hive DDL statements via the Amazon Athena Console or a Hive client on an Amazon EMR cluster. Finally, if we already have a persistent Apache Hive Metastore, we can perform a bulk import of that metadata into the AWS AWS Glue Data Catalog by using our import script.
Anti-patterns
Streaming data – AWS Glue ETL is batch oriented, and we can schedule our ETL jobs at a minimum of 5 minute intervals. While it can process micro-batches, it does not handle streaming data. If our use case requires us to ETL data while we stream it in, we can perform the first leg of our ETL using Amazon Kinesis, Amazon Kinesis Data Firehose, or Amazon Kinesis Analytics. Then store the data in either Amazon S3 or Amazon Redshift and trigger an AWS Glue ETL job to pick up that dataset and continue applying additional transformations to that data.
Multiple ETL engines – AWS Glue ETL jobs are PySpark based. If our use case requires us to use an engine other than Apache Spark or if we want to run a heterogeneous set of jobs that run on a variety of engines like Hive, Pig, etc., then AWS Data Pipeline or Amazon EMR would be a better choice.
NoSQL Databases – Currently AWS Glue does not support data sources like NoSQL databases or Amazon DynamoDB. Since NoSQL databases do not require a rigid schema like traditional relational databases, most common ETL jobs would not apply.